BasicSR
BasicSR - средство для обучения моделей.
На момент написания статьи автор обновил его до версии 1.0. Но нет возможности применить обученную сеть. ESRGAN не готов к данной версии. Поэтому берем ветку сентября 2019 года. Как только заработает актуальная ветка поправлю статью.
Базовая подготовка ОС
О этом вообще можно составить отдельную статью, так как работоспособность на разном железе требует различной установки.
На момент актуальной версии железа nvidia 10, 16 и 20 серии все работает из коробки. Но если нужно завести все на более старом железе, то есть много нюансов.
NVIDIA CUDA
Следуем инструкции установки на реальное железо linux или WSL2. Пока в статье MMEditing, но потом перенесу в отдельную статью.
Python 3
Смотрим версию:
python3 --version
Если Python установлен то покажет версию, если нет то нужно установить.
На данный момент Python есть по умолчанию в ubuntu, если сделать:
sudo apt update sudo apt -y upgrade
pip3
Менеджер пакетов для Python 3
sudo apt install -y python3-pip
PyTorch
С PyTorch все интереснее, для актуального железа ставиться последняя доступная версия:
Выбираем нужную нам конфигурацию
stable
linux
pip
python
cuda 10.2
pip install torch torchvision
Но если железо старое то нужно устанавливать последнюю поддерживаемую версию железо. Везде по своему. В моем случае это tesla m2070:
....
BasicSR
Пакеты для Python
pip install numpy opencv-python lmdb pyyaml
TensorBoard
pip install tensorboardX
git clone -n https://github.com/xinntao/BasicSR.git
cd /tmp/BasicSR
git checkout -b test 00bbaf87163956fd00c22db73d051b9e27bcd563
Идем конфигурировать файл тренировки модели.
Подготовка набора данных
Задача состоит в том, чтобы обучить сеть на восстановление видео снятых на miniDV камеру. Видео хранилось на кассетах, после чего было перенесено на пека, методом захвата с DV камеры. Захват осуществлялся через Firewire. На данный момент это самый максимально возможный с точки зрения качества захват. Нет способов получить качество выше.
В итого имеется 50 гигабайт видео в разрешении 720x576 с соотношением сторон 4:3. Но есть много но. Камера не профессиональная, качество записи не идеальное. Оному производителю известно как получается картинка. Тут будут приложены оригиналы.
- Исходные изображения захваченные с DV
-

-



Первое, что заметно на кадрах, это последствия черезстрочной записи. Подавление черезстрочности выполнено было на этапе подготовки видео для раскадровки. Более качественного подавления черезстрочной развертки я не нашел. Следующая заметная особенность представленных кадров это некое утолщение любых границ объектов, это следствие интерполяции, которая скорее всего выполнялась на самой камере при записи. Интерполяция совсем не простая, но имеет артефакты. Так же присуще любой непрофессиональной записи, небольшой расфокус. Очень большое количество смазанных кадров в различном направлении из за низкой статичности камеры. Слабые "смазы" еще допустимы, но в большинстве случаев они ужасающе сильные, на таких кадрах попросту не за что зацепится.

Говорить о приведении изображения в студийное качество конечно же нельзя, чудес не бывает, но все кадры с более менее сохранившимися деталями сохранить можно.
Следующей проблемой видео является сжатие. При том, что видео захвачено с камеры в сумасшедших 35 мегабитах потока, для разрешения 720x576, не каждый 4к фильм может похвастаться таким потоком, есть множество артефактов, появляющихся при сжатии видео. Причиной тому является невысокая производительность самой камеры, в которой был встроен аппаратный кодек. У кассеты формата miniDV поток как раз примерно равен 35 мегабит. Настолько в те времена аппаратная реализация сжатия была примитивна, что не смогла в такой поток уместить изображение без видимых артефактов. Но в целом, это еще обусловлено сложностью самого изображения, у него высокая зернистость и "пёстрость", что сильно влияет на степень сжатия. Это проблема любых любительских записей.
Итак, выявлены следующие входные данные:
- Интерполяция
- Расфокусирование
- Смазанное изображение
- Артефакты сжатия
Здесь перечислены те проблемы которые можно смоделировать искусственно. Черестрочную развертку смоделировать очень не просто, Так же не просто смоделировать смазывания во всех направлениях и с разной длинной.
По части артефактов сжатия могут возникнуть вопросы - "Слишком незначительно, зачем делать на них акцент", соглашусь, но из этих артефактов возникают паттерны для возникновения более сложных артефактов, сеть будет воспринимать их как объекты и троить вокруг них шум. Поэтому нужно дать понять сети, что такого роба элементы не являются частью изображения.
Сделаю акцент на обучении сети. Самая большая проблема восстановления даже не в алгоритме. А во входных данных. Нужно каким то образом показать сети, что "вот из этого" должно получаться "вот это". И сделать это по меньшей мере 100 тысяч раз, в различных вариациях.
О наборе данных, их много, очень много. Популярны DIV2K, Flickr2K, технически это набор рандомных фото, тысячи фото всего вокруг. Так же я собрал свой сет из библиотеки, из 500 фото. У google есть тоже открытый набор данных в виде 9 миллионов фото. Но такими объемами данных оперировать на обычном ПК невозможно.
После получения наборов данных, лучше всего переименовать все по порядку. Есть 1000 изображений каждое назвать от 0001 до 1000. В именах не должно быть пробелов и спецсимволов, лучше оставить только цифры. Потом попросту будет легче ориентироваться в данных.
В моем случае в наборе DIV2K есть 800 изображений и 200 сравнительных изображений. Этот набор уже заранее так собран, так как подразумевается для машинного обучения. Сравнительные данные нужны для отчета системы нам. Чтобы было понятно в правильном ли направлении двигается сеть. И например каждые 5 тысяч итераций будет преобразовано с помощью обученной сети 200 изображений. Где будет наглядно виден прогресс.
Кратность
Если набор данных предусмотрен для машинного обучения, то размеры изображений будут иметь размеры в пикселях кратные определенному числу, например четырем. Не каждый набор данных будет таким. Так как не все сети нужны для повышения разрешения. В нашем же случае с набором данных нам придется выполнять изменение размеров, как минимум в 4 раза, иногда даже и 16. Из чего выходит необходимость иметь набор данных разрешение которого по обеим сторонам кратен 16. Какого было моё удивление когда я задал вопрос, как преобразовать массивы изображений так чтобы их разрешение обрезалось до кратных 16 по ширине и высоте. При том что все изображения имеют не фиксированное соотношение сторон. Есть фото вертикальные, есть горизонтальные, а есть квадратные.
Программ с таким функционалом не нашлось. Может плохо искал.
Смогла помочь только утилита для Linux, полностью консольная.
apt-get -y install imagemagick
Как выполнить в ней подобную операцию подсказал форум к данной софтине. Вопрос был чуть другой. Человек не хотел отрезать фото, хотел дополнить до кратного двум. Но там есть формула. В которую можно подставить нужные числа.
%[fx:16*int((w+1)/16)]x%[fx:16*int((h+1)/16)]!
где 16 это кратность
в итоге получилось что то такое:
for pic in $(ls *.png); do echo "I:${pic}"; convert ${pic} -resize $(convert ${pic} -format '%[fx:16*int((w+1)/16)]x%[fx:16*int((h+1)/16)]!' info:) /mnt/d/test/AI/Flickr2K/001_V_LRx4/${pic}; echo " - ok"; done
Что тут нужно знать:
for pic in $(ls *.png); - это создание переменной на основе того что лежит в том месте где выполнена команда. То есть нужно перейти в папку с изображениями, и выполнить команду.
можно запустить команду из любой папки, но тогда нужно указывать путь:
for pic in $(ls /mnt/e/test/005/*.png);
pic - Это переменная
Далее цикл do
-resize - означает изменение размера, в оригинале было дополнение изображения.
В конце указан путь куда должны попасть кадры после обработки.
Дунаю команду можно выполнит и без цикла
for pic in $(ls *.png); do echo "I:${pic}"; _____ ; echo " - ok"; done - это цикл, все что в нем заключено, это обычная одноразовая команда.
Ура у нас есть наборы данных нужной нам кратностью.
Теперь на примере DIV2K попробуем разложить его на несколько видов обработки .
Всего 800 изображений. Разложим их по 100. И к каждой сотне применим различные эффекты, при это уменьшим разрешение в 4 раза, так как наша сеть именно во столько раз увеличивает изображения.
Все манипуляции с понижением качества будем делать в Adobe Photoshop.
Как это работает? В Photoshop создается "экшен" своего рода запись применяемых операций. После чего этот записанный скрип можно применить к любому изображению. Так же Photoshop был бы не он, если бы не мог в пакетную обработку. Для этого есть во вкладке Файл - Автоматизация.
Начинаем с создания "экшенов" для разных сценариев "плохих" кадров.
Первый сценарий
-
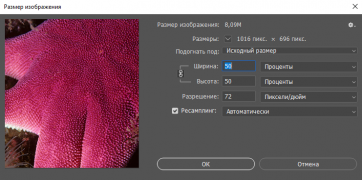 Настройки для уменьшения размера в 2 раза
Настройки для уменьшения размера в 2 раза -
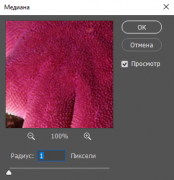 Настройки для применения фильтра - Медиана
Настройки для применения фильтра - Медиана -
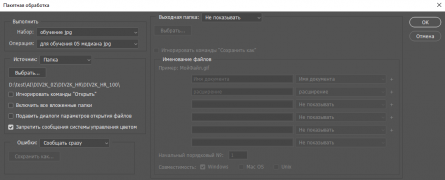 Настройки для выполнения пакетной обработки
Настройки для выполнения пакетной обработки -
 Сравнение результатов
Сравнение результатов -
 Оригинал
Оригинал -
 После обработки
После обработки






- Изменяем размер изображения (50) процентов, нужно это делать в процентах, так как у всех изображений разное разрешение.
- Применяем фильтр Медиана с радиусом 1. Этот фильтр помимо размытия сильно усложняет изображение, с точки зрения математики. Сжимаемость становиться плохой.
- Затем снова снижаем размер изображения на (50) процентов. Это уже будет окончательное разрешение, из которого модель будет стремится получить оригинал.
- Сохраняем в выделенную папку. Зачем? Нам еще осталось выполнить важный пункт ухудшения кадра - Сжатие. Поэтому вовремя записи "Экшена" выполняем сохранение в папку, формат выбираем jpg и сжатие ставим на 4.
Открываем изображение, заканчиваем запись "экшена", и удаляем последнее действие "открыть изображение".
Теперь запускам пакетную обработку. "Выходная папка" выпираем "Не обрабатывать"
"Источник" выбираем "Папка" и выбираем папку с первой сотней изображений.
Начинаем обработку.
В заранее созданной и указанной в "Экшне" папке будут появляться уменьшенные в 4 раза и обработанные согласно "Экшену" изображения, да еще и "пришакаленые" сжатием JPEG.